Ириса: У меня вопрос по добавлению новых слов в словарики. […] Я заметила, что некоторые слова (которые я добавляла) оказывается уже были в более ранних уроках, а некоторые- в более поздних. […] Если слова были в более ранних уроках, то конечно наверно их не надо дублировать еще раз.
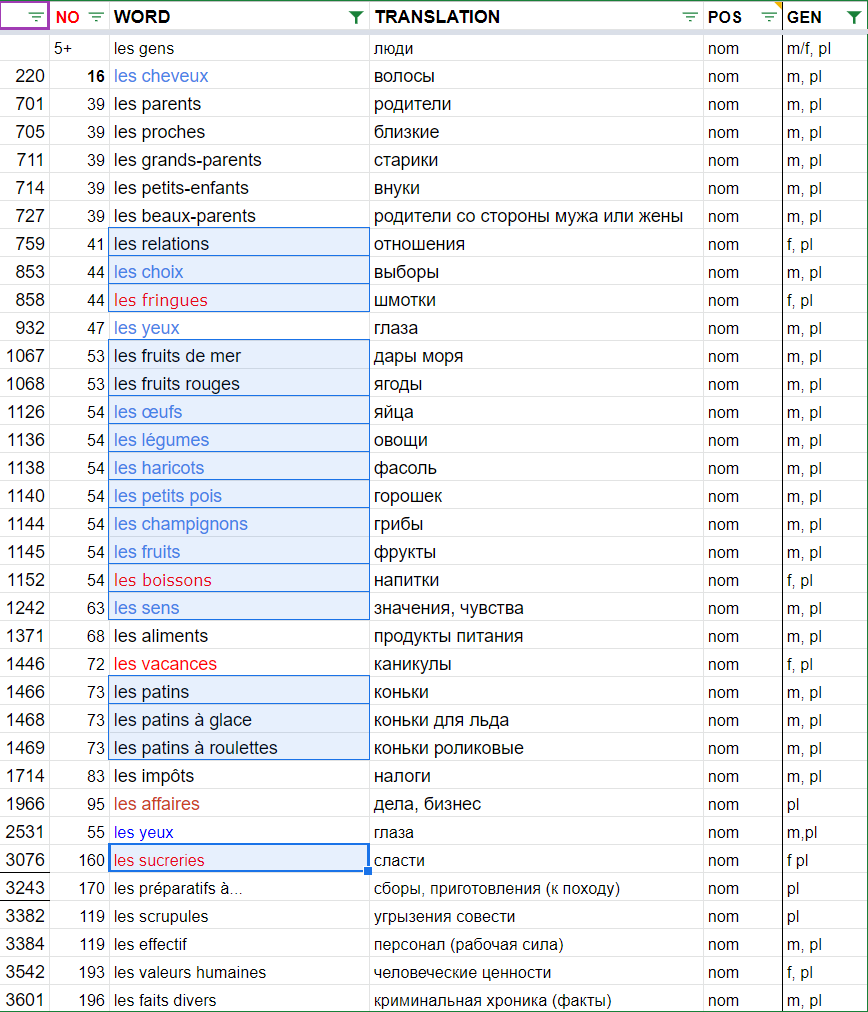
В словаре огромное количество повторяющихся слов. Посколько никаких карточек у меня во времена оные не было, как не было и системы повторений в чистом виде, повторное попадание слов в словарик было своего рода «методом интервального повторения с ручным приводом». Я сегодня рассуждаю так: раз слово плохо запоминалось, забывалось, что оно повторно попадало в словарик, значит, в этом есть свой смысл, значит у такого слова «плохая карма». Ведь и правда, разные слова по-разному запоминаются — какие-то застревают в голове мгновенно, а какие-то приходится зубрить месяцами. Поэтому факт повторного попадания слова в словарик — это, в каком-то смысле, ценная информация.
Чтобы отразить этот факт и сделать использование карточек удобным, мы придумали неплоскую систему хранения слов в базе.
Одинаковые слова выявляются, среди них выделяются группы с разными лексическими значениями. Например, essayer — 1) пытаться, пробовать и 2) примерять одежду.
Одинаковые слова в разное время попадали в разной форме и с разными вариантами переводов, нередко дополняющих один другого. Поэтому у слов в группе есть унифицированное написание слова и унифицированный перевод. Чуть позже мы позволим в настройках пользователям выбирать, хотят они видеть такие слова с одинаковым, унифицированным переводом и написанием, или «пусть будет, как было записано на уроке». Эти унифицированные значения готовлю я перед самой заливкой в базу.
Это своего рода попытка избавиться от груза решений, какие варианты выбирать при составлении словарика: «А! Засунем всё, как есть. Пусть пользователь выберет потом.» Но с другой стороны, это усложняет структуру данных и сам процесс создания словарика.
Поэтому если слово было не прям вот вчера, что называется, его лучше занести. Всегда ведь, при желании, можно слово вычеркнуть в Моих словах или прямо в карточках.
Второй важный момент: если слово находится в группе одинаковых и если пользователь уже учил это слово (проверял себя, и оно прилетало к нему на повторения — или еще прилетит), то есть если однажды для этого слова уже однажды была создана цепочка повторений, то повторное попадание слова в карточки такую цепочку не создаст. Да слово появится в карточках, но в проверку не попадет и на повтор не придет.
Это, в каком-то смысле, делаем попадание повторных слов в словарик безопасным, что ли — оно не создаст пользователю проблем.
Кроме того, можно будет легко сделать настройку: не показывать в карточках повторные слова. Легко — потому что уже на стадии создания словарика мы объединяем такие слова в группы.
Ириса: Я заметила, что есть три колонки - word_orig, translation_orig, pack. Они автоматически заполняются?
Насчет этих служебных колонок. Да, они формируются автоматически. Слово рафинируется (колонка RAFINÉ) — удаляются артикли и все содержимое скобок. И лукапом рафинированное слово ищется среди таких же рафинированных во всем остальном словаре, в том числе и среди новых слов.
Слово может повториться и вчера, и завтра. Нет возможности указать в одной ячейке все случаи повторения, поэтому показывается первое найденное (сперва ищется в BASE, а потом в New Words).

Ириса: Вопрос: как искать слова в таблице base?
Слова в BASE приходится искать только для вкладки BUGS (здесь все ищется само). Я просто ищу поиском по Ctrl-F.