Alexey: И похоже что в автопроизношение роботом кое-где вмешивались чтобы поправить? Огромная работа!
Алексей, спасибо за похвалу и за то, что Вы это заметили и оценили! Там действительно копий было поломано немало. После того, как мы получили окончательный список слов, мы потратили две недели, чтобы привести их в порядок, организовать и озвучить. И на этом пути встретилоась уйма неожиданных проблем.
Во-первых, действительно, слова озвучивались синтезом голоса не так, как хотелось. К счастью, есть Speech Synthesis Markup Language (SSML), язык разметки, который позволяет немного влиять на произносимый текст.
Дело в том, что во французских словах словарика полно фраз, которые обозначают глагольное управлеие или просто в конце фразы идет часто употребляющийся в этом месте предлог. И проблема вот в чем.
Когда мы произносим фразу, обозначающую паттерн, то есть незаконченную фраззу, оборванную на предлоге, мы произносим ее не так, как обычно. Например, фразу «Чтобы пройти к…» мы произнесем с акцентом на [к], то есть не так, как этот же кусок, просто выраванный из текста («Чтобы пройти к Эрмитажу») — pour aller à… или pour aller au/aux....
Еще хуже обстоят дела с предлогом de — французы зажевывают его и произносят его очень кратко: например, фраза mot de passe, которую мы себе представляем, как [мо дё пасс], французы произнесут совершенно не так. Они ее произнесут, как [модпас]. И вот это [д] в середине и есть звук, который у них соответствует предлогу de. В результате все фразы словарика, которые заканчиваются на этот предлог, звучат и непонятно, и неестественно. Например, parle de…, если его в лоб отдать синтезатору, прозвучало бы, как [парлед].
И вот для того, чтобы сделать акцент на предлоге, пришлось в каждую такую фразу вставлять тэги, которые делали бы акцент. На примере фрагмент таблицы. Слева исходная фраза, а справа — фраза, подготовленная для синтезатора.


В ход шло всё — только бы добиться нужного звучания. Запятые и знаки вопроса — мы экспериментировали с тремя системами Text To Speech (Microsoft, Amazon и Google), потому что они по-разному отрабатывали управляющие тэги. И в результате разные типы фраз произносят разные синтезаторы, потому что у каждой что-то получалось лучше, а что-то — хуже…
То есть да, мы не просто нажали кнопочки и сказали: «Горшочек, вари», — нет, мы попотели над этой проблемой. А поскольку списки огромные (на сегодня четыре тысячи слов), пришлось разобраться во всех трех системах, чтбы управлять ими программно (у каждой свой API) и, синтезируя звук, одновременно помещать файлы на сервер, а ссылки на них — в базу. Да, это была непростая задача, которая заняла у нас две недели.
Отдельной проблемой стали для нас дубликаты. Поскольку метод интервальынх повторений никто не отменял, он на занятиях использвался явным образом: когда слово забывалось, оно всплывало на уроках снова и снова. Заносилось в тетрадку и попадало в словарь.
Что с такими словами делать? Поскольку каждое слово в словаре запускает цепочку интервальных повторений, мы не можем на кадую встречу такого дублирующегося слова запускать новую цепочку. Таких слов 15% в полном списке слов, а с учетом их повторений это — ⅓ всего словаря. Как быть?
Мы решили их оставить, но сформировать унифицированный перевод для повторяющихся слов. ПРишлось найти все дубликаты и перевести их одинаковым образом. Но и оригинальный (из конспекта взятый) перевод мы сохранили.
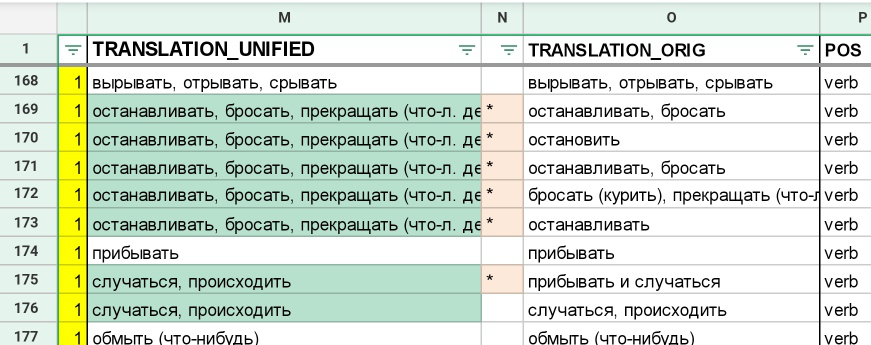
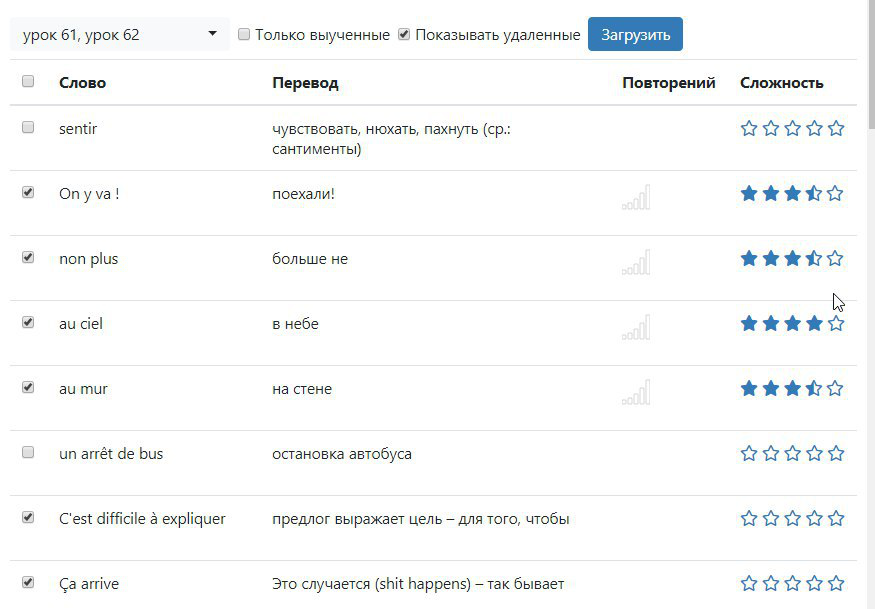
Унифицировать пришлось и французское слово. Следующий скриншот дает понять, насколько различались и слова, и переводы для, фактически, одного и того же слова — их все пришлось унифицировать.
Отдельной задачей были случаи, когда одно и то же слово всплывало на уроке в другом значении. Например, essayer — это пробовать, пытаться, а когда мы дожодим до темы магазина одежды, это — примерять одежду. И слово появляется в словарике в новом значении, а значит его нельзя «склеивать» с предыдущими дубликатами.
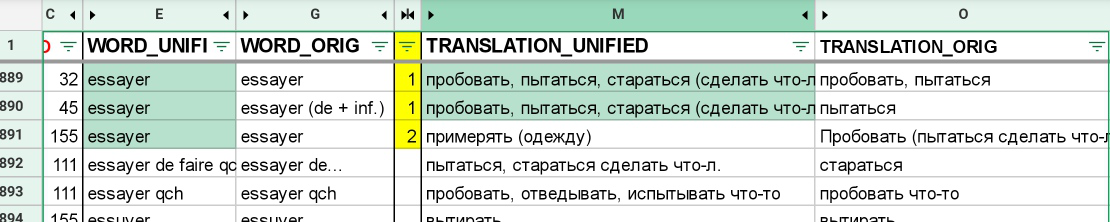
Все такие партные слова, а также их многочисленные значения хранятся в базе тоже. И в поведении приложения мы приняли такой алгоритм поведения: если слово встречается в первый раз, он формирует цепочку повторений. Когда оно встречается повторно, оно есть в списке, который мы прослушиваем (его оттуда можно, при желании, удалить), но оно не идет в проверку и создает новую цепочку — потому что в этом значении это слово уже запущено в интервальные повторения. Но вот если это слово встречается в новом значении, оно идет, как абсолютно новое со всеми вытекающими.
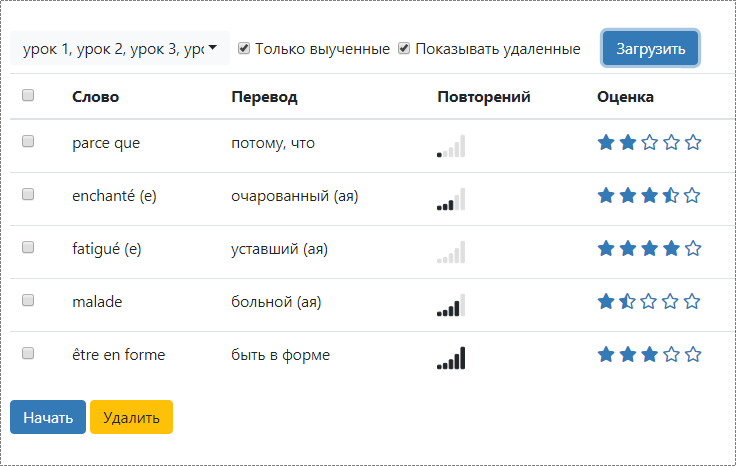
Сегодня мы приступили к работе над инструментом, позволяющими как-то управлть своими словами. Есть такой работающий прототип, пре-альфа. Это фильтр по номеру урока, степени запомненности слова, числу его повторений etc. — по такому фильтру можно получить список слов, чекать и анчекать их и по результату (пока) запустить на повторение (например, самые трудные слова с низшим персональным рейтингом запоминаемости).
Скриншот под спойлером — дюже большой:
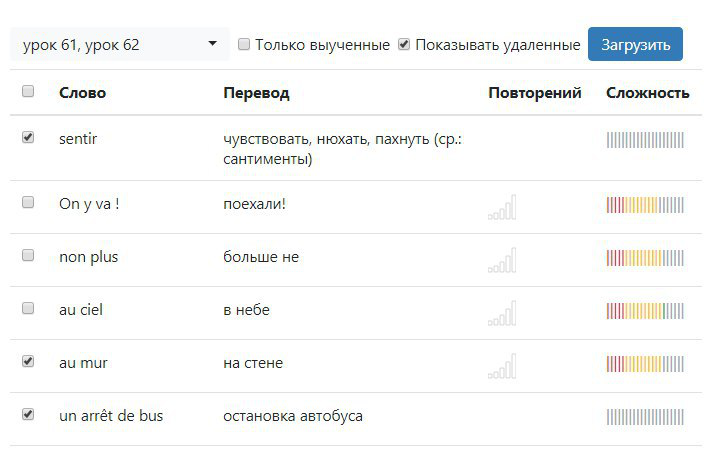
Результат — список слов, удовлетворяющих фильтру:
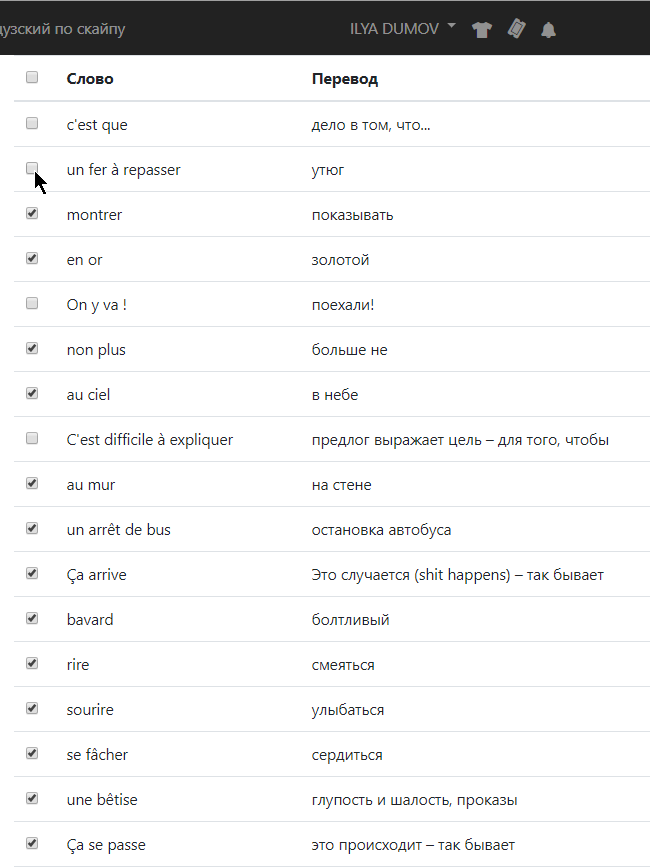
И длаьше этот список можно пустить на авторотацию с произношением (анпример) или сохранить, как именованную выборку (это я мечтаю так:). В общем, мы планируем в будущем дать возможность маниппулировтаь такими списками и изменять атрибуты каждого слова в нем — оставить/вычеркнуть, подвинуть в расписании повторений, поменять степень запоминаемости.
Весь такой функционал будет особенно удобен тем, кто, как Вы, Алексей, или как я, прошел уже много уроков и хочет из большого списка выбрать слова, которые забылись, и дрилить только их, а не повторять bonjour, toujour и merci. ;)
Вот так обстоят на сегодня дела. И да, на подходе запоминака глаголов. Тоже задачка… :)